Google translate
Google Translate звісно є дуже хорошим прикладом використання штучного інтелекту! Саме задопомогою нейромереж, він в змозі перекладати різноманітній текст на різні мови!
Інші перекладачі працюють подібним чином.

Face ID
Face ID в вашому iPhone теж є нейромережею! Саме тому iPhone розпізнає тільки ваше лице, навіть якщо ви виглядаєте по іншому. Технологія під назвою Face ID використовує штучний інтелект, щоб запам'ятати ваше лице, а пізніше зрозуміти, ви це чи ні?

Chat GPT
Chat GPT дуже розумний сьогодні чат бот, який у вигляді переписки дає відповіді на ваші запитання, побажання та інше. Всім сьогодні відомо, що це дуже хороший приклад нейромережі і саме через Chat GPT в наші дні більшість людей зацікавилися цією темою.

Тепер, коли ви вже побачили, що нейромережі зараз насправді справді вже всюди навколо нас, можна починати розбиратися, як саме вони працюють?
Ситуація:
Уявіть в себе в голові хлопця, що навчається в школі і вирішує контрольну роботу з алгебри. І ось він доходить до останнього рівняння, фіналу, де треба знайти три змінні A, B та С і отримати якусь відповідь. Він вирішує завдання хоч якось і випадково помічає в свого сусіда правильну відповідь. Вона дорівнює 10, а в нього в задачі вийшло 74 тисячі, який жах. І що ж робити? Треба прорішати рівняння спочатку, але часу на це вже немає, тому він вирішує швиденько підставити значення під правильну відповідь. Вчителька помічає те, що хлопець підставляє значення під правильну відповідь і ставить йому 2.



Тепер запамʼятайте цю історію, тому що
тільки що я дав вам опис методу навчання нейромережі, який дозволив їм змінити світ назавжди!
Але спочатку нам треба розібратись, взагалі, що таке нейромережа?
ЩО ТАКЕ НЕЙРОМЕРЕЖА?
Всі нейромережі мають схожі структури. Вони складаються з нейронів. Нейрон можна уявити як скриньку з двома отворами, вхідним і вихідним, в якій зберігається якийсь обмежений діапазон значень, найчастіше це числа від 0 до 1. У вхідний отвір поступають числа (зазвичай їх дуже багато), а у вихідний отвір подається лише одне число. Нейрони зібрані у різні стовпчики, так звані шари, яких буває дуже багато. Найперший шар називається «вхідним», саме в нейрони цього шару подаються вхідні дані. Це наприклад числа що вказують на колір кожного пікселя на картинці, або відстані до обʼєктів в грі.
Модель нейромережі:
Далі йдуть сховані(по центру) шари. В нейронах даних шарів виконуються деякі математичні дії, які покращують правильність відповіді нейромережі і передають число далі і далі. В кінці воно приходить у вихідний шар нейромережі. І той нейрон вихідного шару, який тримає в собі найбільше значення, вважається відповіддю,
Добре, структура здається зрозуміла, але що за дані передають по шарам і яка це математика виконується в середині нейронів?
Розберемо на прикладі
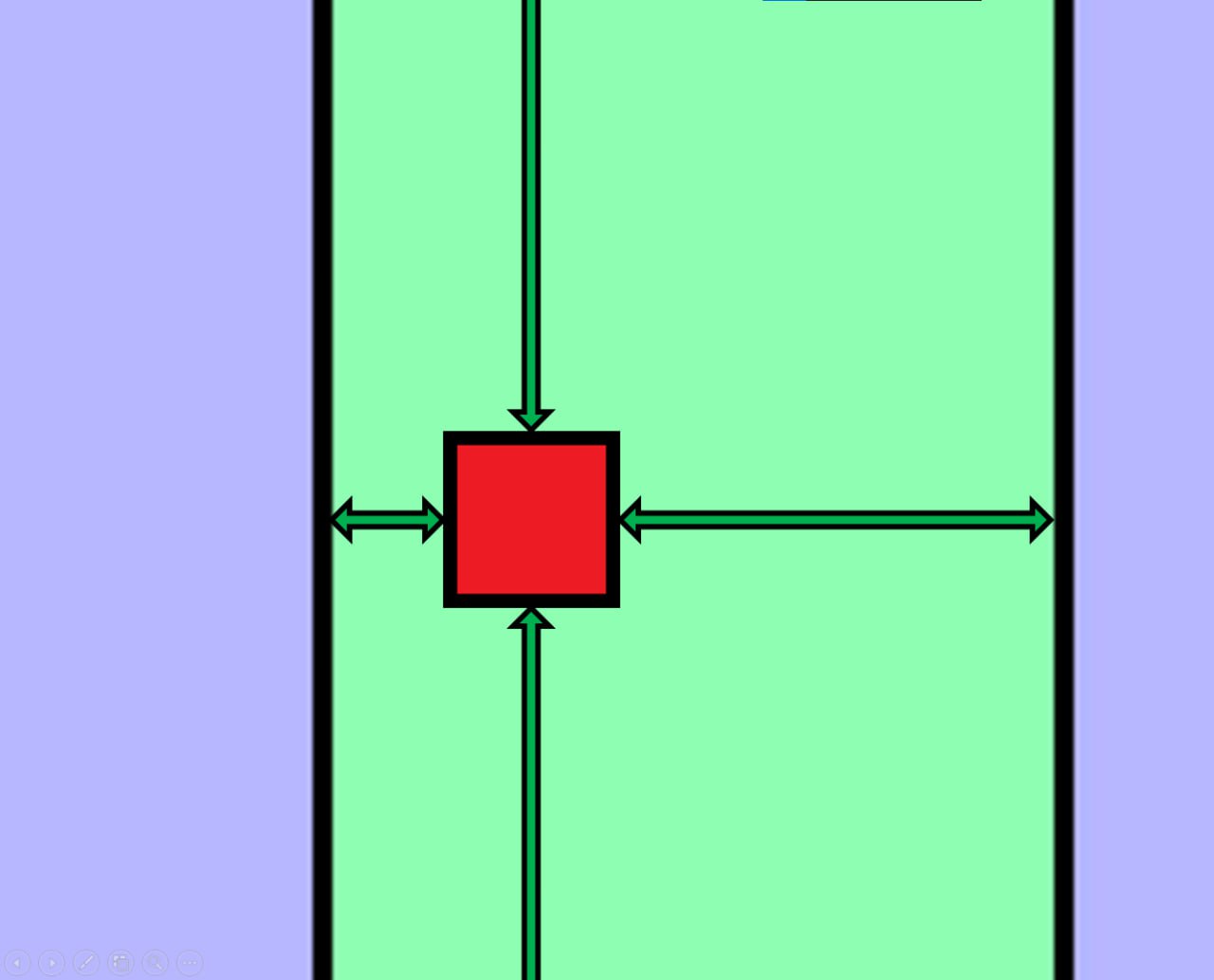
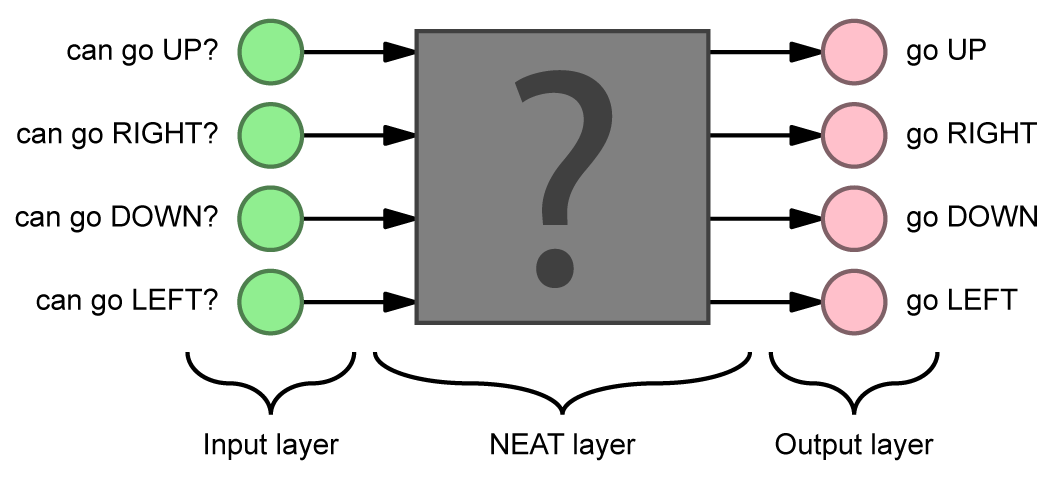
Хай ми граємо в гру, де гравець – це червоний квадрат. Як вхідні дані, ми маємо відстані до найближчих стін навколо. В нейромережі кожен нейрон шукає окрему ознаку, яка буде впливати на відповідь, отже подивимось як думає окремий нейрон. В нього, як і в інші, поступає сума всіх значень з нейронів вхідного шару. Хай саме цей буде розумітися на тому, чи треба зараз йти вправо.
Логічно, що ми можемо присвоїти різним відстаням до різних стін різні коєфіцієнти, наприклад ми припускаємо, що щоб йти вправо, нам треба виділити відстань, що веде до лівої стіни, тоді в даному нейроні завищені коєфіцієнти будуть саме у цієї відстані, а в інших відстаней понижені. Такі коєфіцієнти в нейромережах прийнято називати «вагами», в формулах вони позначаються літерою W. Тепер дивіться. Перемножуючи кожну відстань на коєфіцієнти ми можемо зрозуміти, чи достатньо близько ми до лівої стіни, для того, щоб йти вправо. Якщо дана ознака знайдена, тобто ми достатньо близько, то в нейрон буде записане велике число, а якщо ні, то маленьке.
Перетягуйте мишкою гравця:
A:
C:
B:
D:
МОЖНА ЙТИ ВПРАВО
Але для того щоб активувати нейрон, нам треба подати туди достатньо велике число, тобто число, яке вище якогось значення. Інакше, нейрон не буде нічого передавати далі і якби вибувати з гри, деактивуючись.
Ми знаємо, що нейрон може тримати в собі значення від 0 до 1, але от вхідні дані можуть бути набагато більшими. Мало того що ми сумуємо всі ці значення, ми ще й множимо їх на ваги. Тому отримане значення нам треба нормувати, тобто призвести до правильного вигляду. Для цього використовуються функції активації, такі як tanH, або RELU наприклад.
Функція :
Отже формула в нейронах: f(A*W1 + B*W2 + C*W3 + D*W4);
де f - функція активації(наприклад RELU). A, B, C та D - вхідні дані. W1, W2, W3, W4 - ваги.
Зрозуміло, що для кожного нейрона задавати ваги треба індивідуально, але даних значень неймовірна кількість в навіть найпростіших нейронних мережах. То як знайти ці правильні коєфіцієнти? А насправді ніяк. Ми спочатку просто даємо рандомні значення вагів для нашої нейромережі, і тому ми отримуємо повністю випадкові відповіді. І тут ми можемо згадати ситуацію з школярем. В нас є перевага, ми знаємо правильні відповіді, і це значить що в кожному конкретному випадку, ми можемо вказати нейромережі на те, наскільки сильно вона помилилась.
Тут вступає в силу алгоритм зворотного розповсюдження помилки, в чому його сенс?
Алгоритм зворотного розповсюдження помилки
Хай ми стоїмо дуже близько до стіни зліва, це значить що нам треба рухатися вправо, а значить що в нейроні в вихідному шарі, який вказує на рух вправо мала б стояти одиничка, а в усіх інших нейронах, нулі. Це означало б, що нейромережа повністю впевнена, що їй треба рухатися вправо. Але ми отримали інші значення і знаючи правильні відповіді ми можемо відняти від правильної відповіді відповідь нейромережі, отримавши число, яке вказувало б, наскільки нейромережа помилилась.
А далі, знаючи ступінь помилки, ми можемо відрегулювати ваги та інші можливі коєфіцієнти, до правильних значень для кожного нейрона пропорційно тому, наскільки вони були винні в помилці. Звісно ми не зможемо знайти правильні значення одразу, на це треба багато спроб, оскільки з кожною спробою ми будемо покращувати значення коєфіцієнтів.
ЩО ТАКЕ NEAT?
Нейронні мережі зазвичай використовуються в завданнях кластеризації (по іншому класифікації) і розпізнавання образів. І ось в завданнях розпізнавання образів структура нейронної мережі (її топологія) зазвичай задається заздалегідь. Сам вибір топології мережі є дуже нетривіальним завданням, яке виникає ще задовго до навчання самої мережі. Тому постало завдання, щоб мережа могла не лише навчатися, а й сама налаштовувати свою топологію, створювати/вилучати вузли та зв'язки. Одним із таких алгоритмів є алгоритм NEAT, саме його ми сьогодні розглянемо.
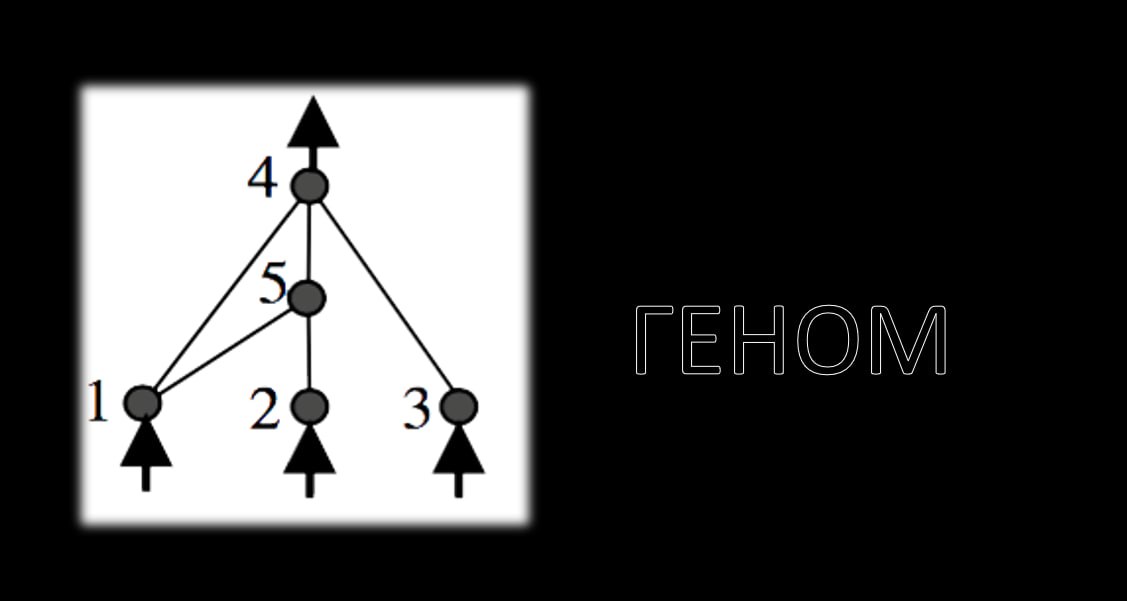
Алгоритм NEAT – це еволюційний алгоритм. Він дозволяє використовувати генетичні алгоритми для визначення кращої та мінімально необхідної топології нейронної мережі. Вся структура самої нейромережі є такою самою, як я вам тільки що розповів. Декілька шарів, вхідні, вихідні шари, ваги та інше, все тут так само є. Так як нейромережа постійно себе перебудовує, вона має зберігати свої нейрони, щоб потім їх переставляти, змінювати, активувати/деактивувати, та інше. Тому набори нейронів (на малюнку вони прономеровані) та зв'язків зберігаються в, так званий, «Ген» або «Геном».
Так як NEAT використовує генетичний алгоритм, який схожий за системою на еволюцію, описану Дарвіном, то з видами стаються мутації/зміни. Вони бувають двох видів. При першій мутації може додатись зв'язок до вже існуючих нейронів. При другому типі мутації створюється новий нейрон, на місці вже існуючого зв'язку між двома нейронами. При цьому старий зв'язок стає неактивним, і створюються два нових. В обох випадках новим зв'язкам буде надано новий історичний маркер (унікальне число - ID). Ці ж історичні маркери використовуються при схрещуванні, щоб зрозуміти як змішати два гени.
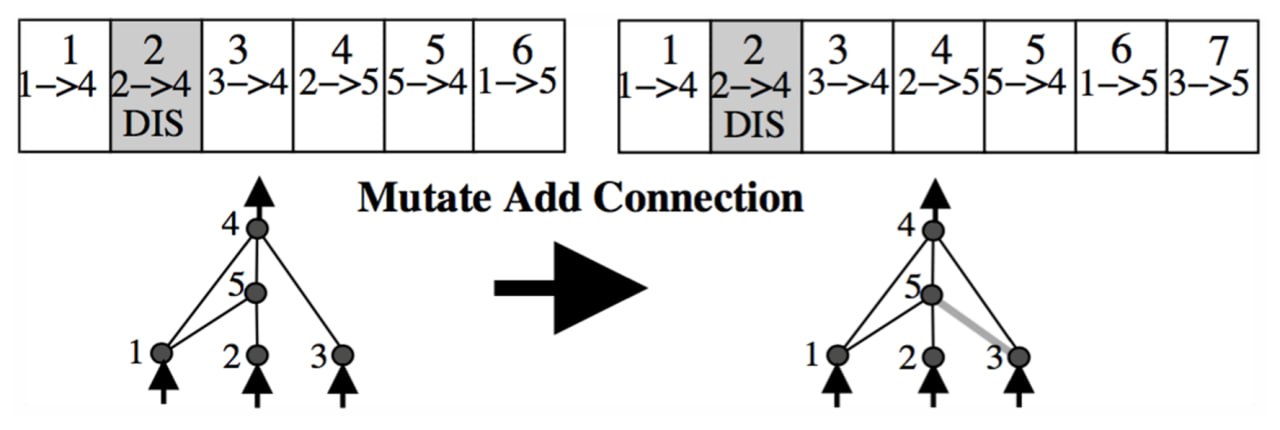
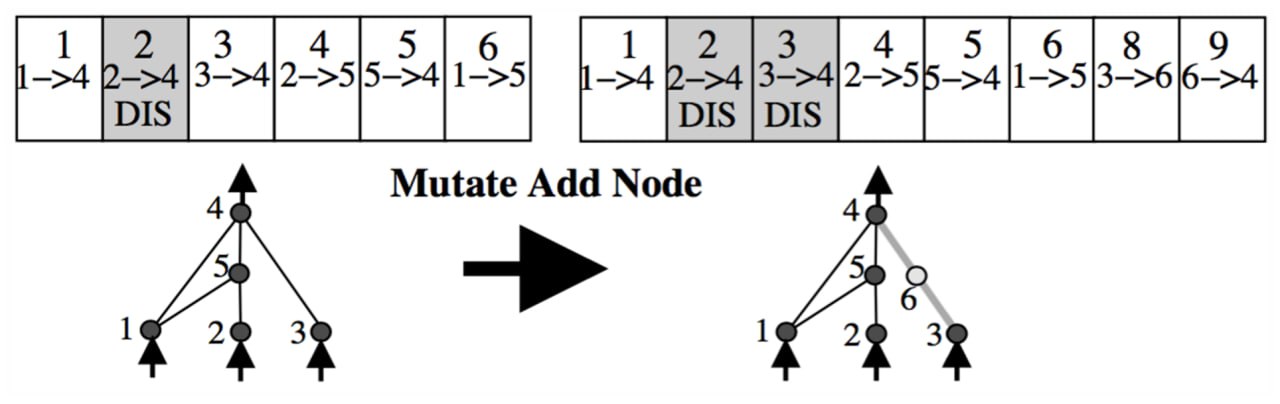
Якщо ви уважно подивилися на цей малюнок, у вас могло виникнути питання, а чому після мутації в нас утворилися звʼязки 8 і 9, а не 7 і 8. Сенс в тому, що тут ми бачимо, для прикладу мутацію, одного гена з якоїсь повноцінної нейромережі, тобто це не єдиний ген, а лише один маленький з великої кількості інших. Річ у тому, що такий історичний маркер надається одному звʼязку для всіх геномів у нейромережі, тобто в даному гені зліва, ми маємо звʼязок 1 – 5 з історичним маркером 6. І в усіх інших генів, такий звʼязок так само буде мати ID 6 і інший звʼязок з таким історичним маркером зʼявитись не може.
Якщо ми повернемося назад, ми побачимо, що при мутуванні даного гена в той, в якому додався звʼязок між нейронами 5-3, ми цьому звʼязку присвоїли ідентифікатор 7. І в наступному гені, на наступному малюнку, ми не можемо присвоїти новим звʼязкам номер 7, оскільки він вже привʼязаний, до іншого звʼязку, в даному випадку звʼязку між нейронами 3 та 5.
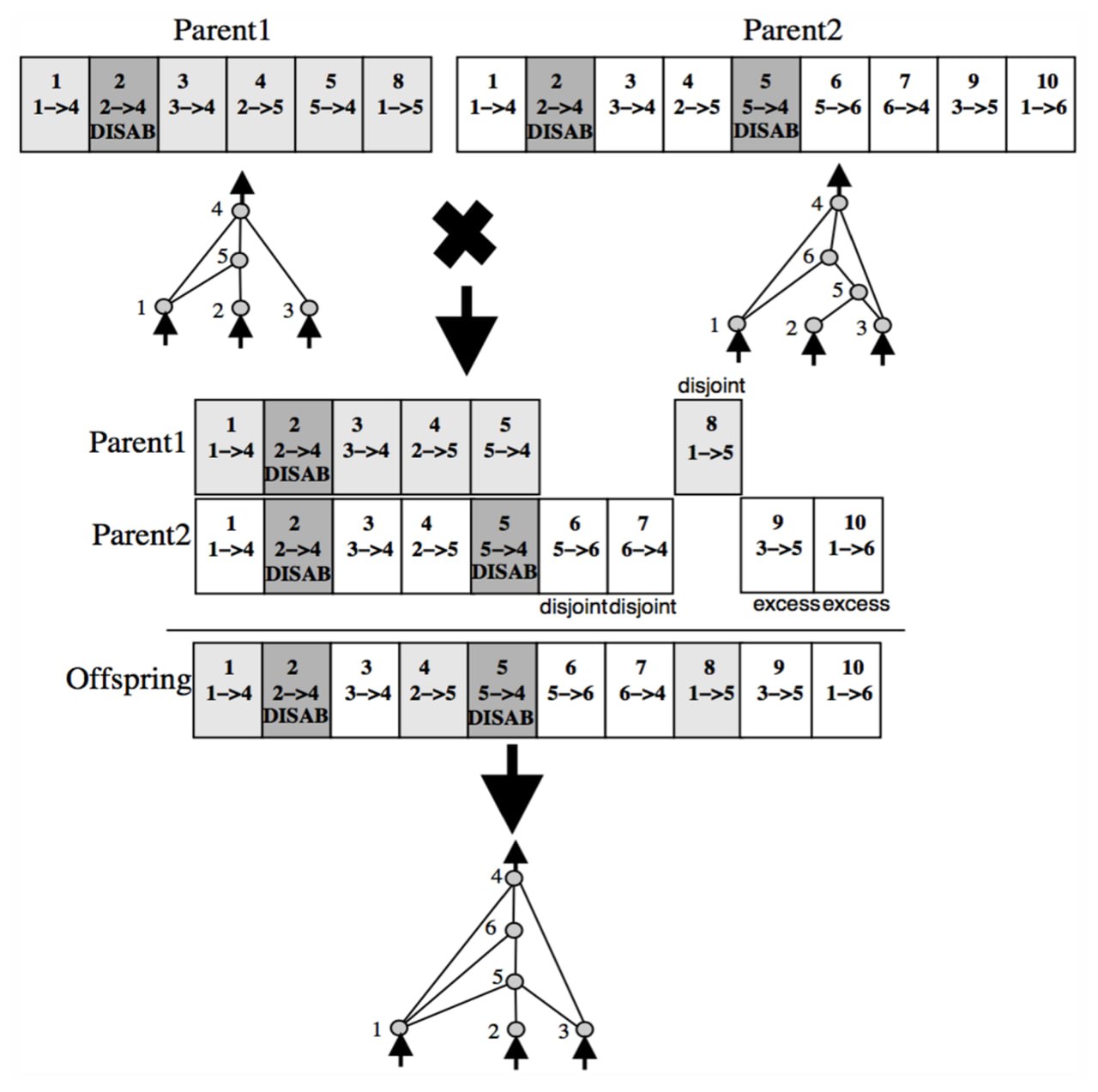
Як відбувається схрещування?
А для цього потрібно всього лише в ген нащадок внести всі унікальні історичні маркери обох батьків. Якщо зв'язок неактивний в одного з батьків, то у нащадка він також буде неактивним. Якщо зв'язок неактивний у обох батьків, то він має шанс мутувати і стати активним у нащадка. Це як в математиці, при множенні – на + отримуємо - , при множенні – на -, можемо отримати + (шанс 50 на 50 відсотків).
Як працює генетичний алгоритм?
Як і в будь-якому генетичному алгоритмі створюється початкова популяція. Спочатку кожна особина складається лише з пронумерованих вхідних та вихідних нейронів. Кожен вхідний нейрон пов'язаний із вихідним. В кожного генома є спеціальний параметр fitness. Ми маємо збільшувати цей параметр, коли ми вважаємо, що нейромережа робить правильно і зменшувати, коли не правильно. Далі до кожної особи застосовується фітнес-функція, вона схожа на метод зворотного розповсюдження помилки. Вона визначає те, наскільки ця особина підходить для виконання покладених на неї функцій.
Ця фітнес функція перевіряє всю популяцію і ті особини, які виявилися кращими за інших, матимуть великі ймовірності на "продовження роду", але навіть гірші мають невеликий статистичний шанс. Це потрібно для того, щоб нейромережа не зупинилась на місці в своєму розвитку.
Далі алгоритм відбирає особин з урахуванням отриманих ймовірностей та відбувається "схрещування". Найчастіше саме схрещування – найскладніша частина генетичних алгоритмів. За його допомогою генерується повністю нова популяція, лише дуже рідко можуть братися кілька особин колишнього покоління та додаватися до нового покоління. Після чого відбувається мутація, тобто значення ваги з певною ймовірністю змінюються, і випадково додаються нові зв'язки/нейрони. Після цього цикл повторюється.
Таких циклів/популяцій може бути дуже багато. Для простих задач вистачає 4-5 популяцій, а от для більш складних 300 і навіть більше 1000 поколінь.
Навчання в іграх
Спочатку може бути складним уявити, яким чином нейромережа навчається. Тому для демонстрації я розробив копії трьох відомих ігор (Flappy Bird, Undertale, The world's hardest game) і запустив туди нейромережу. Таким чином, в ігровому процесі, ви зможете побачити те, як нейромережа прогресує. Випробувати ці ігри ви можете завантаживши додаток.
Натиснувши на кнопки зверху, ви можете побачити, яким саме чином навчається ШІ в поданих іграх: які вхідні дані їй даються, за що вона нагороджується, за що її карають. Таким чином вам буде легше зрозуміти, що саме відбувається.
Натиснувши на кнопку "Car simulation" ви перейдете на сторінку, де зможете побачити симуляцію, де нейромережа навчається водити машину:
Вже на самій сторінці симуляції трошки подробніше розписано, як все працює.